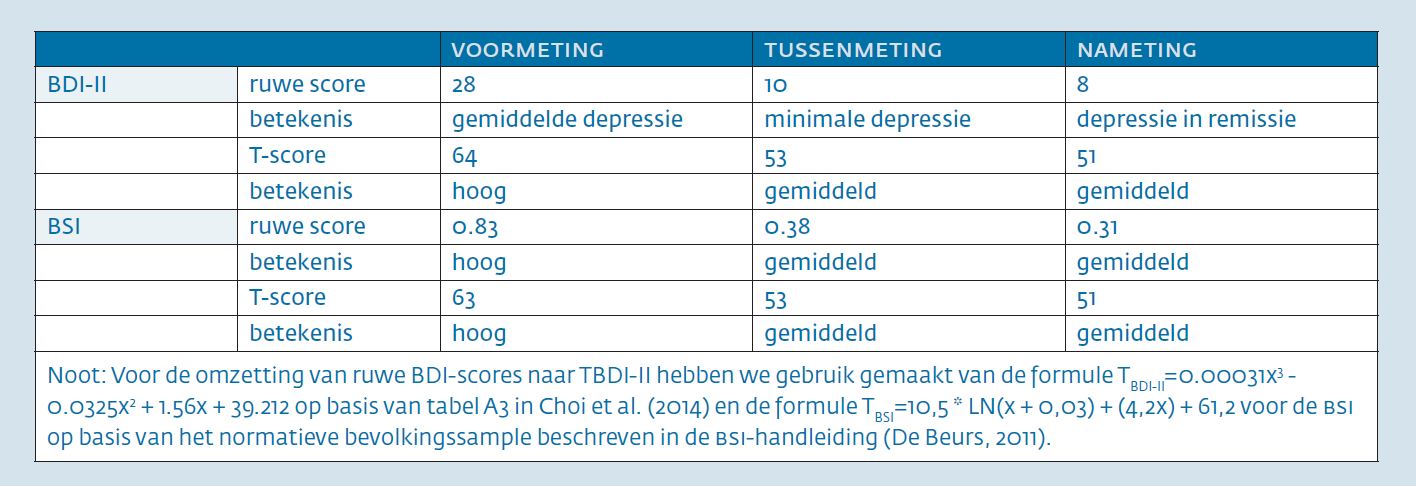
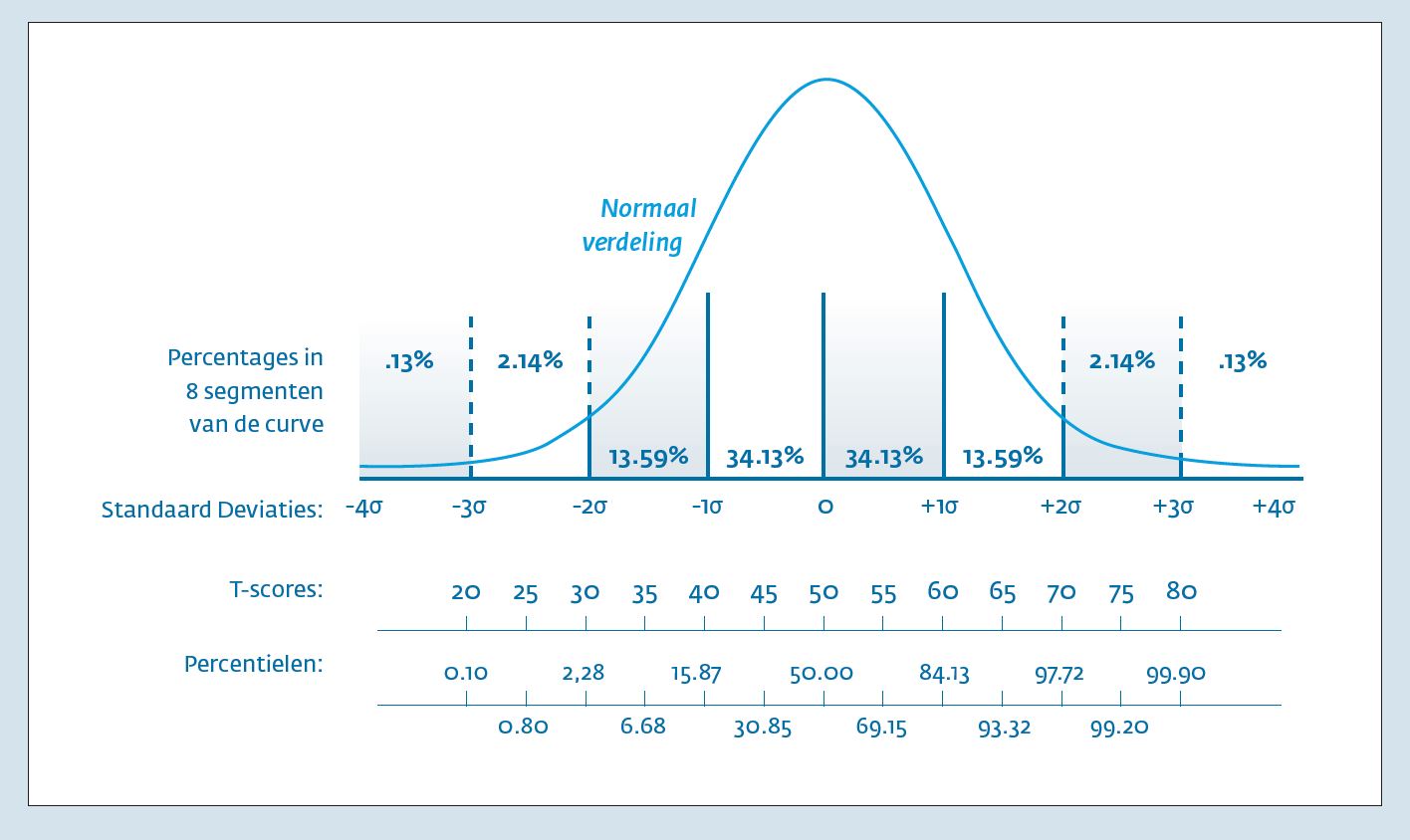
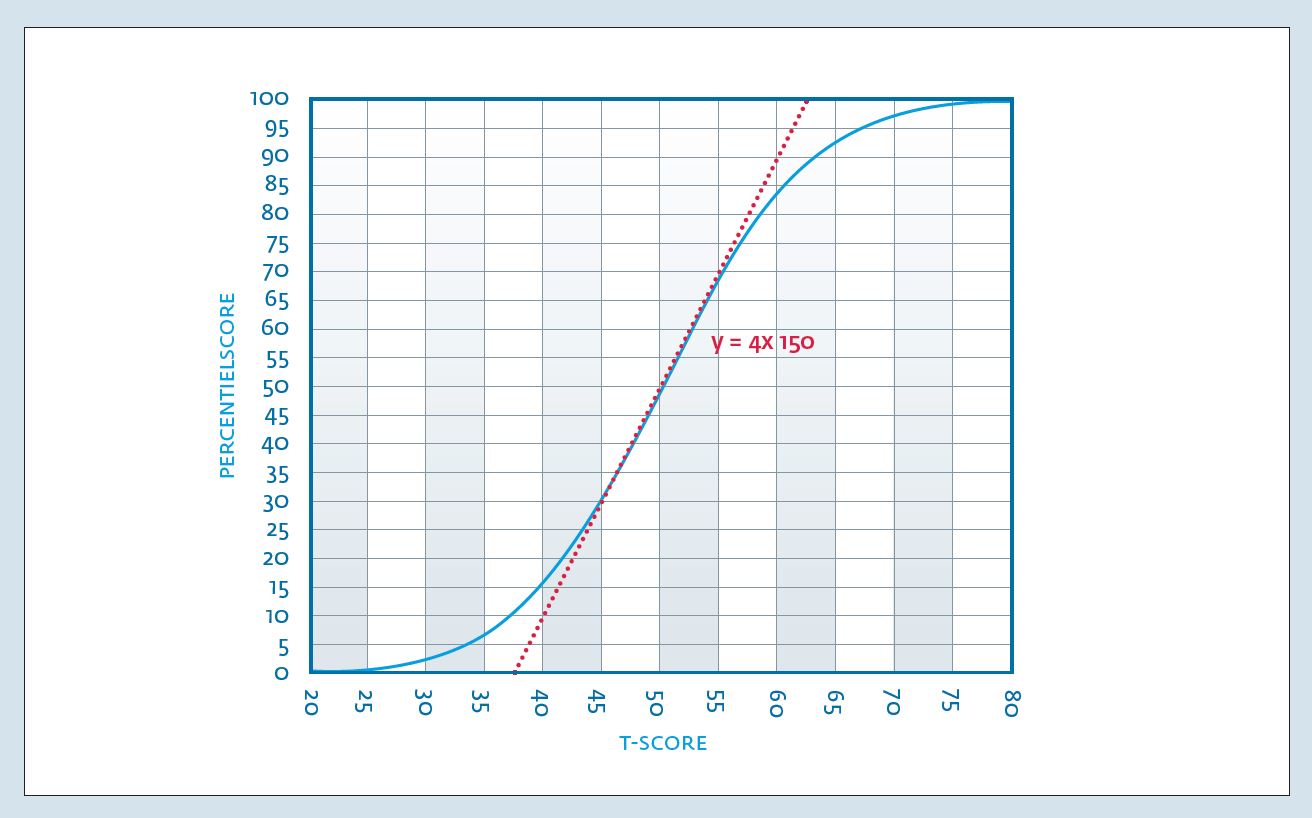
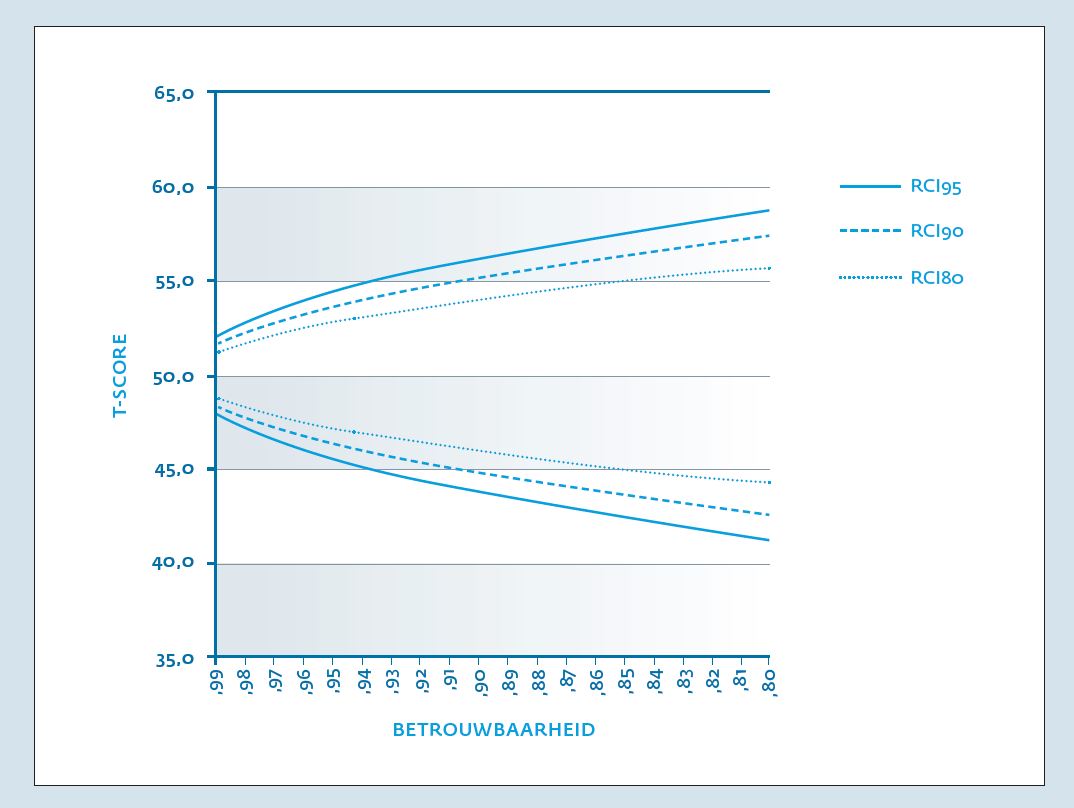
Inleiding
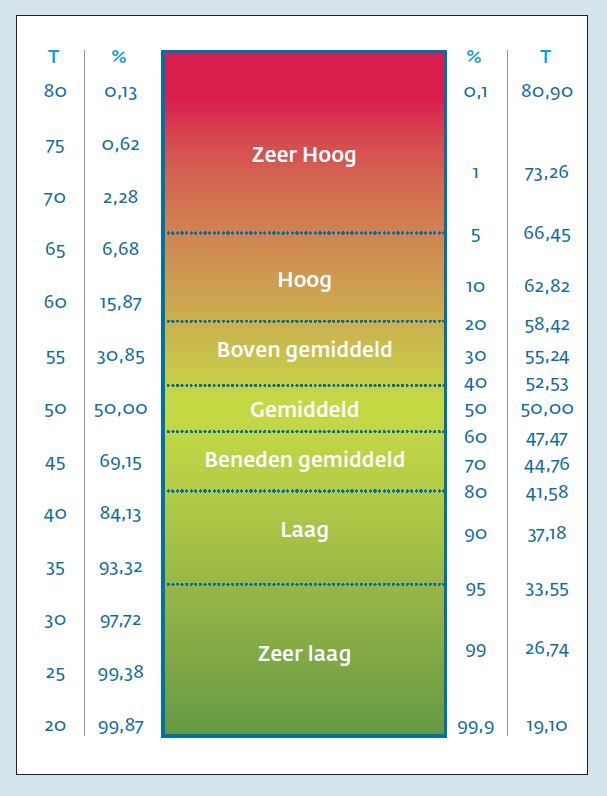
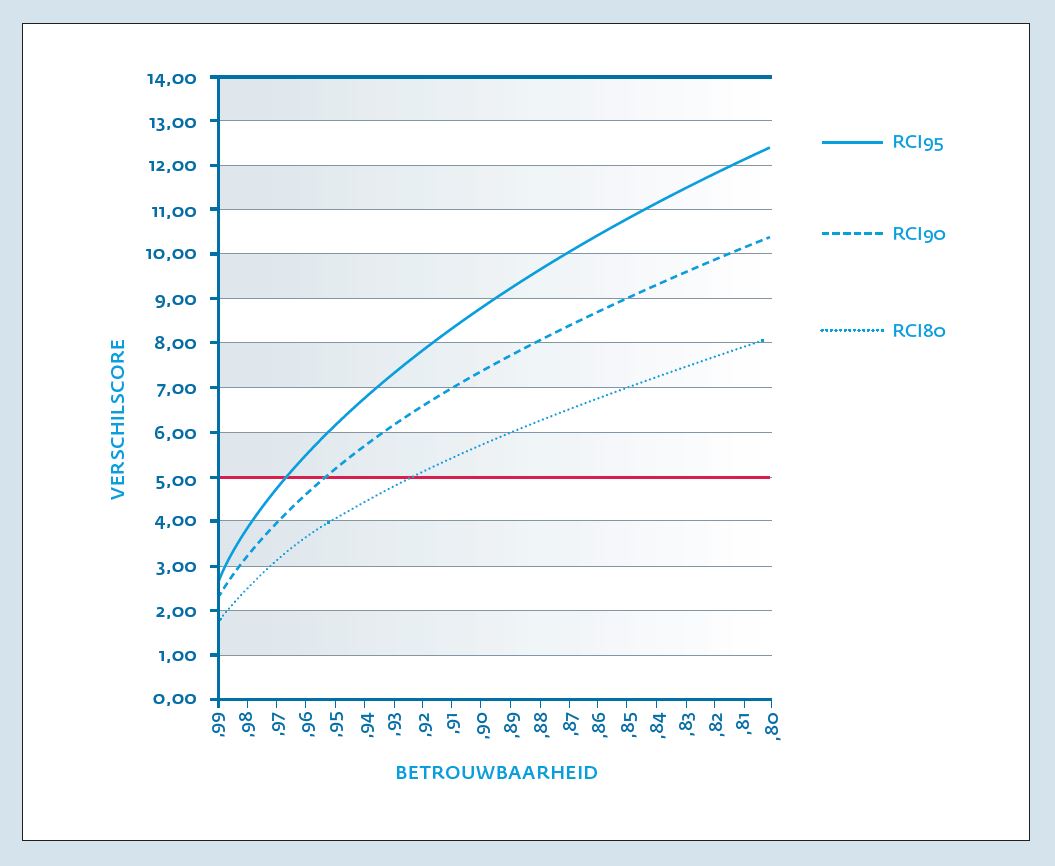
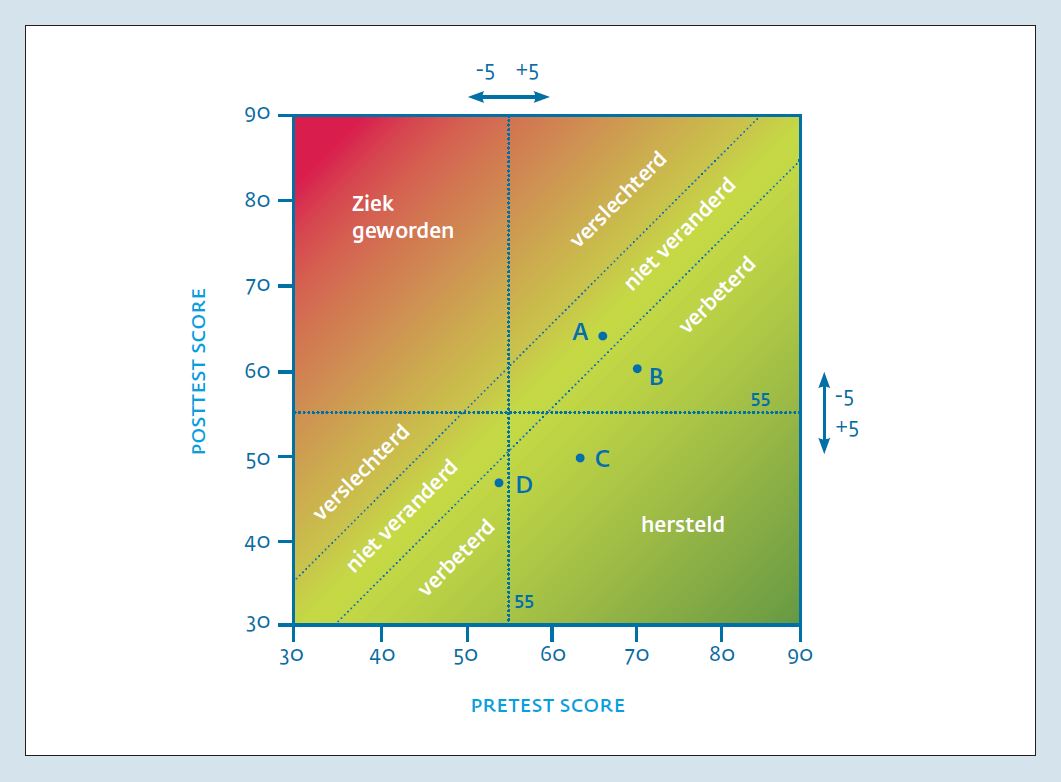
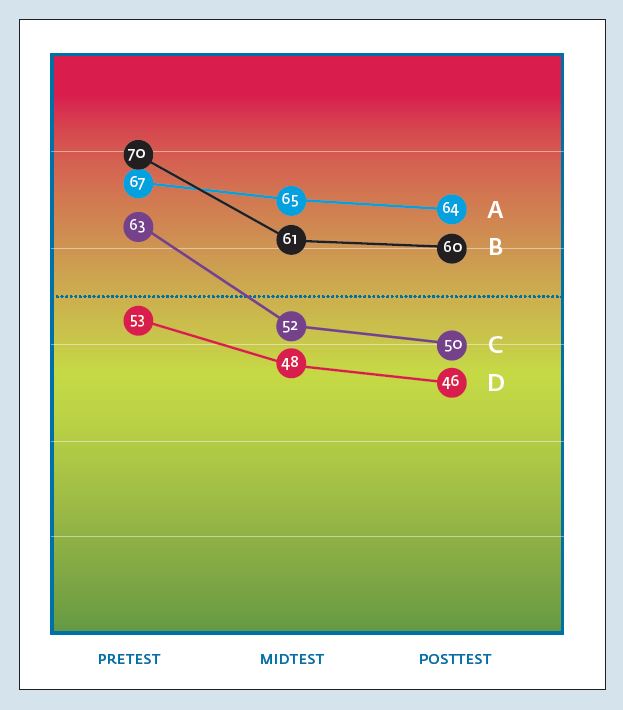
Gebruik van meetinstrumenten in de klinische psychologie wordt al geruime tijd gepropageerd en hun toepassing in het kader van Routine Outcome Monitoring (ROM) neemt hand over hand toe. Veel professionals in de zorg zijn echter onvoldoende vertrouwd met meetresultaten en voelen zich onvoldoende toegerust om de patiënt goed voor te lichten over de gegevens die ROM oplevert. Het helpt daarbij niet dat de gebruikte meetinstrumenten in de ggz allemaal hun eigen meetschalen hebben en er talloze cryptische afkortingen voor subschalen worden gebruikt. Hierdoor is eerst een grondige studie van het meetinstrument vereist, alvorens iets met de scores aan te kunnen vangen. Een medicus heeft het wat dat betreft iets makkelijker met een enkele schaal voor koorts, een enkele schaal voor bloeddruk en een enkele schaal voor de hemoglobinewaarde van het bloed. Ook is kennis over de interpretatie van scores, met name waar het gaat om verandering in de score over de tijd, nog onvoldoende verspreid. Zo